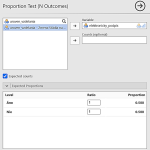
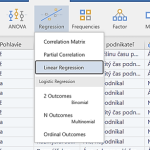
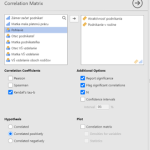
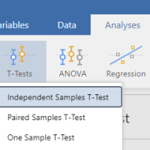
Na poskytovanie tých najlepších skúseností používame technológie, ako sú súbory cookie na ukladanie a/alebo prístup k informáciám o zariadení. Súhlas s týmito technológiami nám umožní spracovávať údaje, ako je správanie pri prehliadaní alebo jedinečné ID na tejto stránke. Nesúhlas alebo odvolanie súhlasu môže nepriaznivo ovplyvniť určité vlastnosti a funkcie.
Technické uloženie alebo prístup sú nevyhnutne potrebné na legitímny účel umožnenia použitia konkrétnej služby, ktorú si účastník alebo používateľ výslovne vyžiadal, alebo na jediný účel vykonania prenosu komunikácie cez elektronickú komunikačnú sieť.
Technické uloženie alebo prístup je potrebný na legitímny účel ukladania preferencií, ktoré si účastník alebo používateľ nepožaduje.
Technické úložisko alebo prístup, ktorý sa používa výlučne na štatistické účely.
Technické úložisko alebo prístup, ktorý sa používa výlučne na anonymné štatistické účely. Bez predvolania, dobrovoľného plnenia zo strany vášho poskytovateľa internetových služieb alebo dodatočných záznamov od tretej strany, informácie uložené alebo získané len na tento účel sa zvyčajne nedajú použiť na vašu identifikáciu.
Technické úložisko alebo prístup sú potrebné na vytvorenie používateľských profilov na odosielanie reklamy alebo sledovanie používateľa na webovej stránke alebo na viacerých webových stránkach na podobné marketingové účely.